Registration
Overview
Teaching: 40 min
Exercises: 10 minQuestions
What is a data repository?
What are types of data repositories?
Why should you upload your data to a data repository?
How to choose the right database for your dataset?
Objectives
Define what is data repository.
Illustrate the importance of indexed data repository
Summarize the steps of data indexing in a searchable repository
What is a data repository?
It is a general term used to describe any storage space you use to deposit data, metadata and any associated research. Kindly note that database is more specific and it is mainly for the storage of your data.
Types of data repository
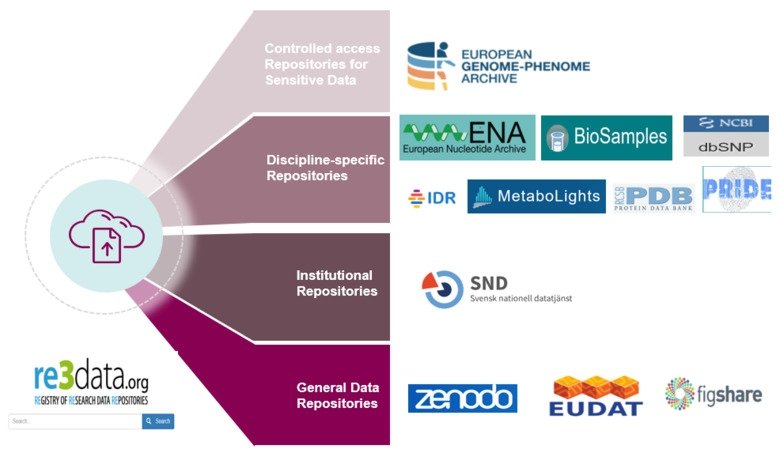
Data repositories are classified based on the purpose of data repository into:
A) Controlled access repository for sensitive data: explained in details in data sharing lesson of RDMkit and we will explain this type of repository in the next episode
B) Discipline specific repository: there are known repository for different data types e.g Arrayexpress for high-throughput functional genomics experiments
C) Institutional repository: In case you can not find suitable repository for your data set, some universities have their own general purpose repositories. For instance, University of Reading Research Data Archive is a general purpose repository that have similar features e.g. controlled access … etc to other databases. It can be used for students and researchers.
D) General data repository: these are usually for data that have no public repositories e.g. Zenodo
Figure 1 summarizes these types with different examples
Why should you upload your data to a data repository?
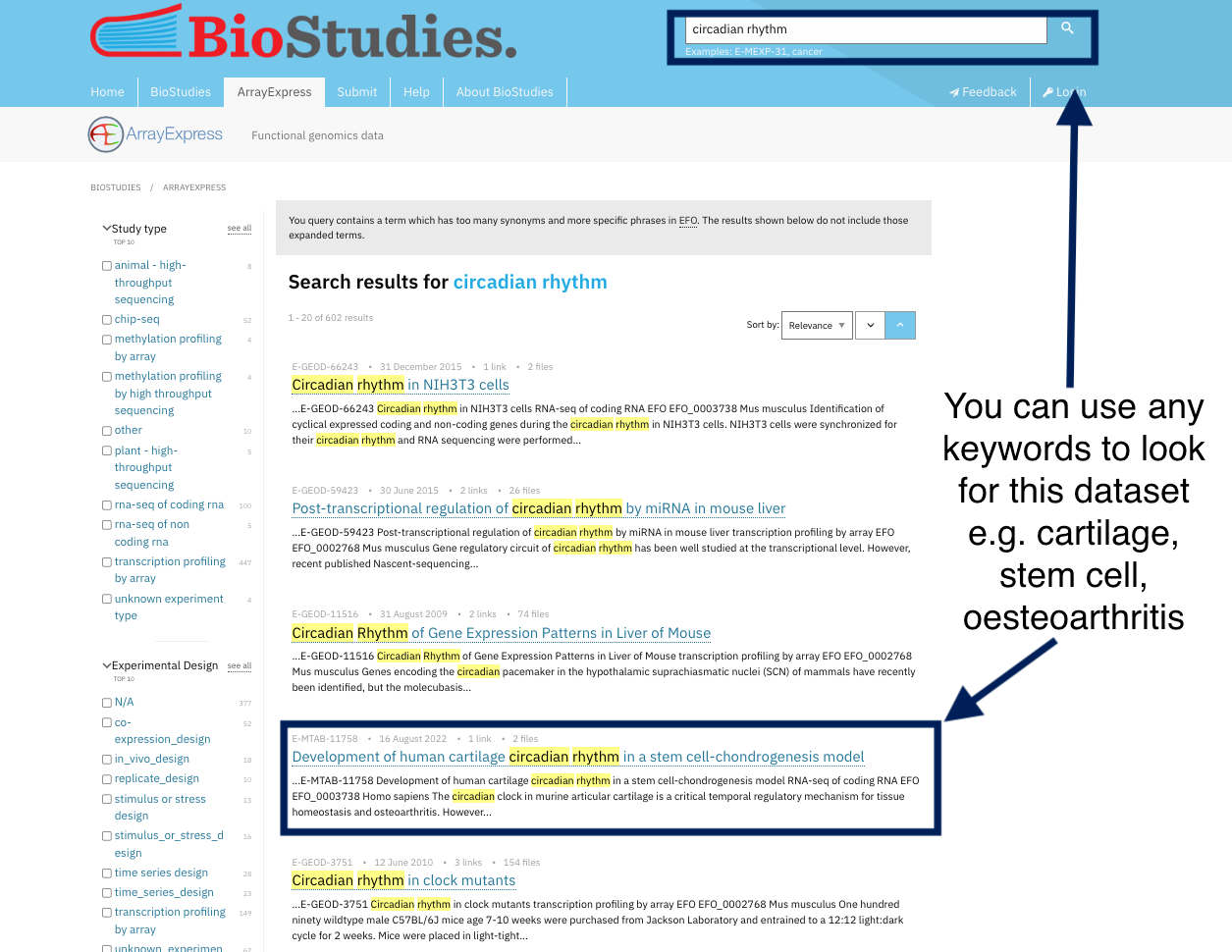
To ensure data findability, your data should be uploaded to a public repository where it can be searched and found, This will make it comply with the fourth principle of findability (F4) which states that (Meta)data are registered or indexed in a searchable resource. Examples of these databases are ArrayExpress for high-throughput functional genomics experiments. These databases have a set of rules in place to make sure that your data will be FAIR. After you upload your data into this database, they are assigned an ID and are indexed. Indexing helps researchers find your data by using persistent identifiers, keyword or even the name of researcher.
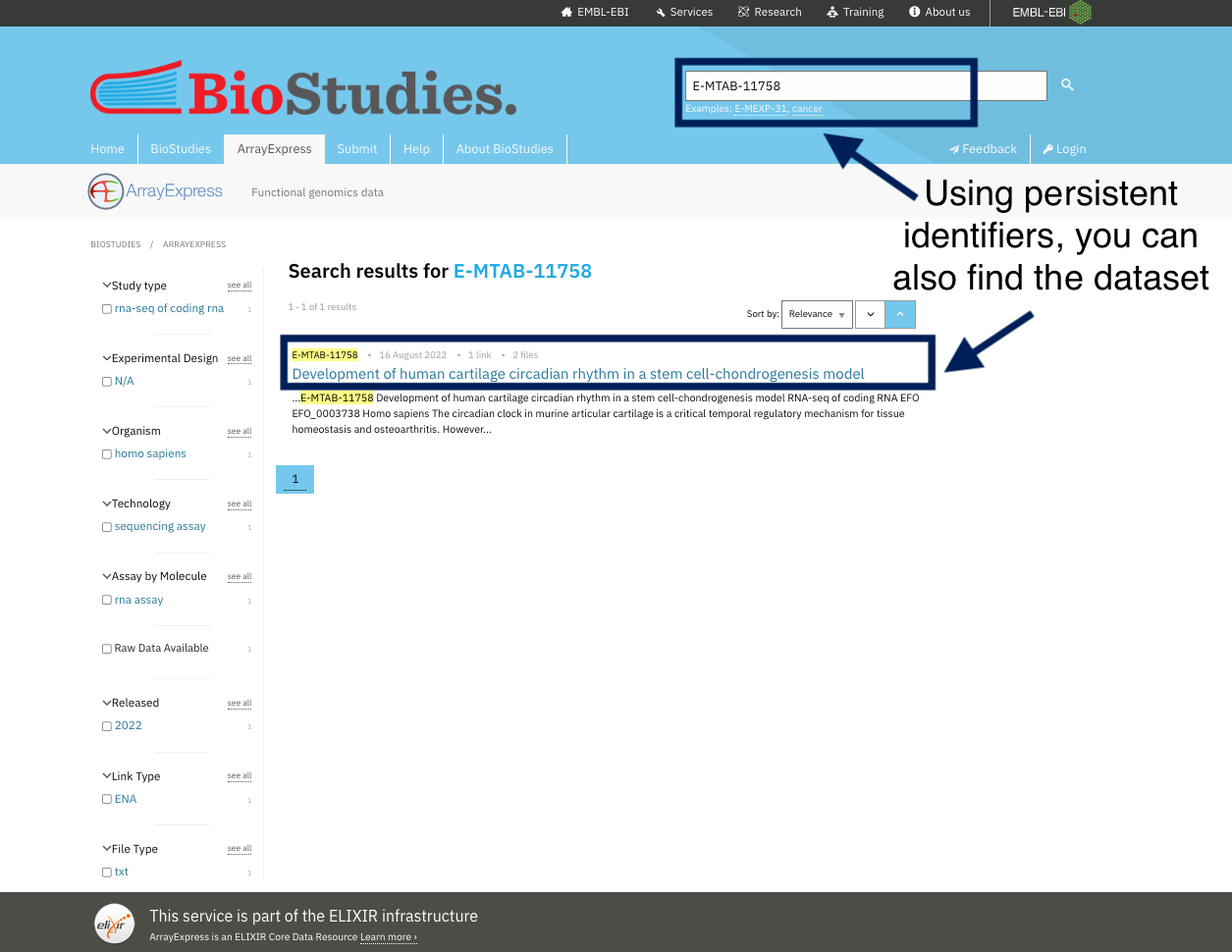
Take a look at the ArrayExpress database where all datasets are indexed, and you can simply find any dataset using the search tools. By indexing data, you can get the dataset using any keyword other than the PID. For example, if you want to locate human NSCL cell lines, you can just type this into the search toolbox, use different keywords like cartilage, stem cells and oesteoarthritis, and you will find the same dataset. Indexing and registering datasets, also means they are curated in such a way that you may discover them using different keywords.
For example, you can find the same dataset by using its identifiers or by using keywords chosen by the dataset’s authors to describe it.
Exercise 1. How to index your dataset?
One of the things you can do to index your dataset, is to upload it to Zenodo, can you use one of the resources we recommended before to know how to do this? RDMkit, FAIRcookbook, FAIRsharing
Solution
Since you want a technical guideline, FAIRcookbook and RDMkit are the best to start with. We will start with FAIRcookbook First of all, let’s understand the structure of the FAIRCookbook. For a quick overview, you can watch our RDMBites on FAIRcookbook FAIRcookbook RDMBites
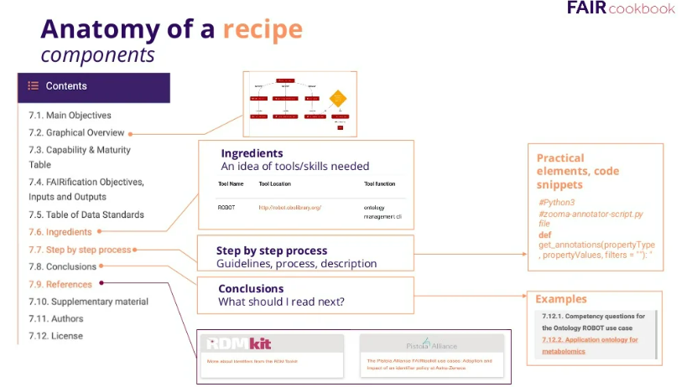
The building unit of FAIR cookbook is called a recipe, The recipe is the term used to describe instructions for how to FAIRify your data. As you see in the image, the structure of each recipe includes these main items Figure 2: 1- Graphical overview which is the mindmap for the recipe 2- Ingredients which gives you an idea for the skills needed and tools you can use to apply the recipes 3- The steps and the process 4- Recommendations of what to read next and references to your reading
As we explained the structure of the recipe so let’s look for the suitable recipe in the FAIRcookbook So as you navigate the homepage of FAIRcookbook, you will find different tabs that covers each of FAIR principles, so for instance, if you want recipes on Accessibility of FAIR, you will find all recipes that can help you make your data accessible.
- Follow the following steps to find the recipe:
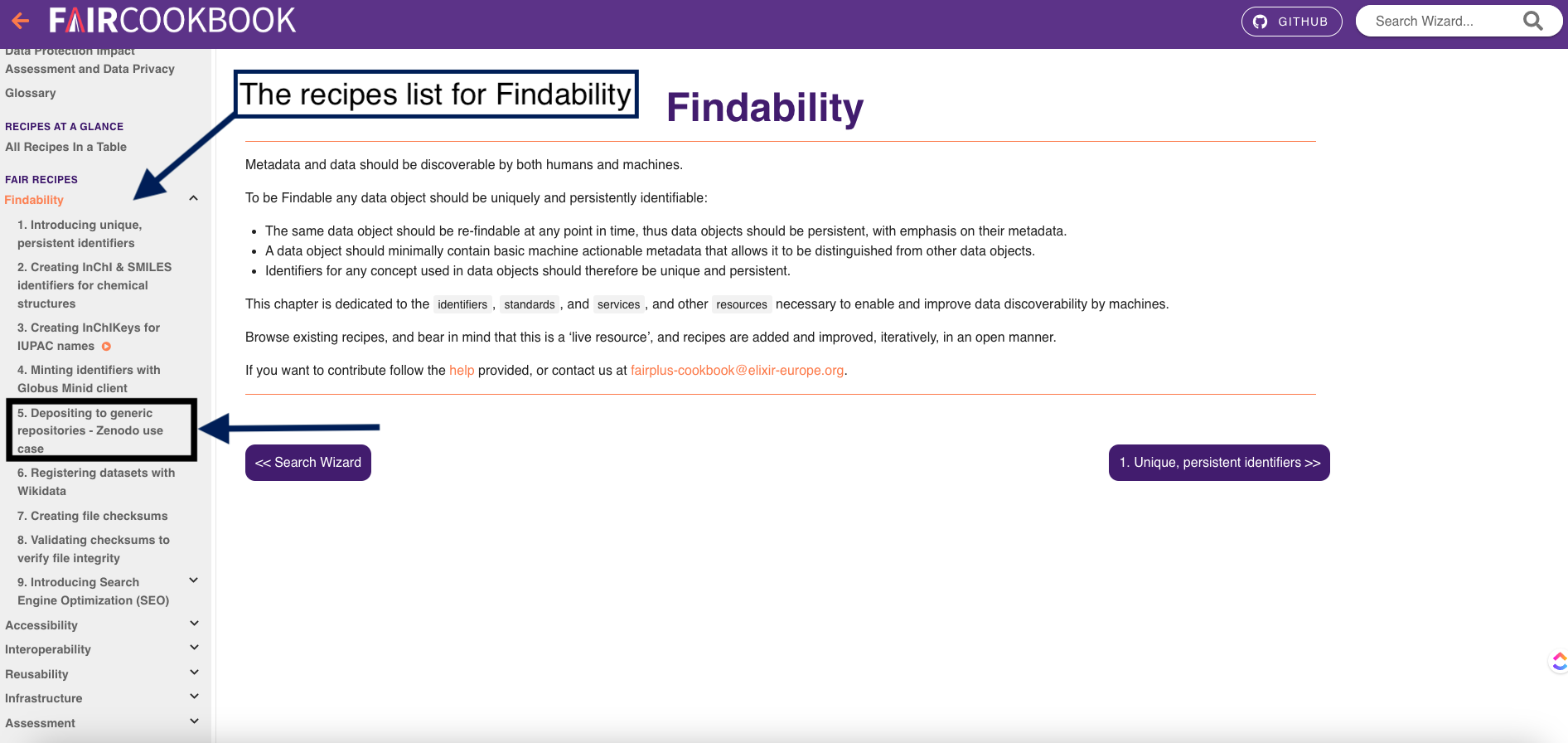
1- In this exercise, we are looking for a recipe on indexing or registering dataset in a searchable resource which you can find it in the findability tab, Can you find it in this picture?
2- Click on the findability tab
3- on the left side, you will find a navigation bar which will help you find different recipes that make your data findable.
4- As you can see here, you will find a recipe on registering datasets with Wikidata and another one on depositing to generic repositories-Zenodo use case Once you click on one of these resources, you will find the following:
A) Requirements to apply the recipe to your dataset B) The instructions C) References and further readings B) Authors and licence
In our specialized courses, we will give you examples on how to upload your data to discipline specific repository


Uploading your data to a database will make your data visible through the following:
1- Databases assign a unique persistent identifier to your data.
2- Your data will be indexed and curated, making it easier to find.
3- Some databases make it simple to connect your dataset to other datasets and link metadata to other dataset linked metadata
4- Dataset licencing, with some databases offering controlled or limited access to protect your data.
By uploading data to a database, you comply with the following FAIR principles
- F1 (Meta)data is assigned a globally unique and persistent identifier
- F3 Metadata clearly and explicitly include the identifier of the data they describe
- F4 (Meta)data is registered or indexed in a searchable resource It will also allow your data to be more accessible as the standardized communications protocol and authentication are automatically set for your data
- A1 (Meta)data is retrievable by their identifier using a standardised communications protocol
- A1.1 The protocol is open, free, and universally implementable
- A1.2 The protocol allows for an authentication and authorisation procedure, where necessary
- A2 Metadata is accessible, even when the data is no longer available
- I3 (Meta)data include qualified references to other (meta)data
- R1.1 (Meta)data is released with a clear and accessible data usage license
How to choose the right database for your dataset?
University of Reading provides an overview of the necessary criteria to choose a data repository. We can summarize it in the following bullet points:
- Check funders recommendations It is always better to upload your data to funders recommendied data repositories. For instance, Biotechnology and Biological Sciences Research Council (BBSRC) funds and recommend many databases including European Bioinformatics Institute
- Publishers Publishers prefers discipline specific repository, check guidelines before you submit your manuscript.
- Community standards Check the community standards for your data, you can find more information RDMkit guidelines
- If you still cannot find the right one for you, look for resources that describe the databases and check if it fits your data, you might consider the following:
A) Accessibility options
B) Licence
- One of resources that can help you is FAIRsharing, it provides a registry for different databases and repositories. Here is an example where the FAIR sharing provides you with information regarding protein database. It has the following information
- General information
- Which policies use this database?
- Related community standards
- Organization maintaining this database
- Documentation and support
- Licence
Exercise 1. How to choose the right dataset?
You are a researcher in plant sciences and want to know what are the available databases for plant genomes?
Solution
It is the time to introduce you to FAIRsharing, an important resource for metadata standards, databases and policies. The FAIRsharing is an important resource for researchers to help them identify the suitable repositories, standards and databases for their data. It also contains the latest policies from from governments, funders and publishers for FAIRer data. In the following short video, you can find that plant ensembl is the one you can use for the plant genes
Resources
Our resources provide an overview of data repositories and examples
The FAIR cookbook and RDMkit both provide excellent instructions for uploading your data into databases:
- FAIRcookbook recipe on Depositing to generic repositories- Zenodo use
- FAIRcookbook recipe on Registering Datasets in Wikidata
- RDMkit guidelines on Data publications and depostion
- RDMkit guidelines on Finding and reusing existing data
- FAIRcookbook recipe on Search engine optimization
- FAIRsharing offers a nice portal to different examples of databases
Key Points
{“This episode covers the following FAIR principles”=>nil}
(Meta)data are registered or indexed in a searchable resource (F4)
(Meta)data are released with a clear and accessible data usage licence (R1.1)